C/C++ Basics
如何定义一个只能在堆上(栈上)生成对象的类?
只能在堆上
方法:将析构函数设置为私有
原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
只能在栈上
方法:将 new 和 delete 重载为私有
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
内存、栈、堆
一般应用程序内存空间有如下区域:
- 栈:由操作系统自动分配释放,存放函数的参数值、局部变量等的值,用于维护函数调用的上下文
- 堆:一般由程序员分配释放,若程序员不释放,程序结束时可能由操作系统回收,用来容纳应用程序动态分配的内存区域
- 可执行文件映像:存储着可执行文件在内存中的映像,由装载器装载是将可执行文件的内存读取或映射到这里
- 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,如通常 C 语言讲无效指针赋值为 0(NULL),因此 0 地址正常情况下不可能有效的访问数据
栈
栈保存了一个函数调用所需要的维护信息,常被称为堆栈帧(Stack Frame)或活动记录(Activate Record),一般包含以下几方面:
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 保存上下文:包括函数调用前后需要保持不变的寄存器
堆
堆分配算法:
- 空闲链表(Free List)
- 位图(Bitmap)
- 对象池
“段错误(segment fault)” 或 “非法操作,该内存地址不能 read/write”
典型的非法指针解引用造成的错误。当指针指向一个不允许读写的内存地址,而程序却试图利用指针来读或写该地址时,会出现这个错误。
普遍原因:
- 将指针初始化为 NULL,之后没有给它一个合理的值就开始使用指针
- 没用初始化栈中的指针,指针的值一般会是随机数,之后就直接开始使用指针
基类为什么需要虚析构函数?
答:标准规定:当derived class经由一个base class指针被删除而该base class的析构函数为non-virtual时,将发生未定义行为。通常将发生资源泄漏。
解决方法即为:为多态基类声明一个virtual 析构函数。
指针和引用的区别
本质:指针是一个变量,存储内容是一个地址,指向内存的一个存储单元。而引用是原变量的一个别名,实质上和原变量是一个东西,是某块内存的别名。
指针的值可以为空,且非const指针可以被重新赋值以指向另一个不同的对象。而引用的值不能为空,并且引用在定义的时候必须初始化,一旦初始化,就和原变量“绑定”,不能更改这个绑定关系。
不过如下的写法也是通的过编译器的:
1
2
int *iptr = NULL;
int& iref = *iptr;
但是,上面的写法是非人类的。
对指针执行sizeof()操作得到的是指针本身的大小(32位系统为4,64位系统为8)。而对引用执行sizeof()操作,由于引用本身只是一个被引用的别名,所以得到的是所绑定的对象的所占内存大小。
指针的自增(++)运算表示对地址的自增,自增大小要看所指向单元的类型。而引用的自增(++)运算表示对值的自增。
在作为函数参数进行传递时的区别:指针作为函数传输作为传递时,函数内部的指针形参是指针实参的一个副本,改变指针形参并不能改变指针实参的值,通过解引用*运算符来更改指针所指向的内存单元里的数据。而引用在作为函数参数进行传递时,实质上传递的是实参本身,即传递进来的不是实参的一个拷贝,因此对形参的修改其实是对实参的修改,所以在用引用进行参数传递时,不仅节约时间,而且可以节约空间。
上面是引用和指针的区别,总的来说,如果你需要一个可能会为空,或者还会指向别的值的时候,就使用指针,如果是要一开始就要指向一个object,并不会改变的时候就可以只用引用。
深拷贝和浅拷贝的区别
答:浅拷贝:如果在类中没有显式地声明一个拷贝构造函数,那么,编译器将会根据需要生成一个默认的拷贝构造函数,完成对象之间的位拷贝。default memberwise copy即称为浅拷贝。
此处需要注意,并非像大多数人认为的“如果class未定义出copy constructor,那么编译器就会为之合成一个执行default memberwise copy语义的copy constructor”。 通常情况下,只有在default copy constructor被视为trivial时,才会发生上述情况。一个class,如果既没有任何base/member class含有copy constructor,也没有任何virtual base class或 virtual functions, 它就会被视为trivial。
通常情况下,浅拷贝是够用的。
深拷贝:然而在某些状况下,类内成员变量需要动态开辟堆内存,如果实行位拷贝,也就是把对象里的值完全复制给另一个对象,如A=B。
这时,如果B中有一个成员变量指针已经申请了内存,那A中的那个成员变量也指向同一块内存。如果此时B中执行析构函数释放掉指向那一块堆的指针,这时A内的指针就将成为悬挂指针。
因此,这种情况下不能简单地复制指针,而应该复制“资源”,也就是再重新开辟一块同样大小的内存空间。
STL
关于shared_ptr使用需要记住什么?
总结下来需要注意的大概有下面几点:
- 1)、尽量避免使用raw pointer构建shared_ptr,至于原因此处不便于多讲,后续还有讲解
- 2)、shared_ptr使得依据共享生命周期而经行地资源管理进行垃圾回收更为方便
- 3)、shared_ptr对象的大小通常是unique_ptr的两倍,这个差异是由于Control Block导致的,并且shared_ptr的引用计数的操作是原子的,这里的分析也会在后续看到
- 4)、默认的资源销毁是采用delete,但是shared_ptr也支持用户提供deleter,与unique_ptr不同,不同类型的deleter对shared_ptr的类型没有影响。
网络
主机字节序与网络字节序
主机字节序(CPU 字节序)
概念
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址
- 小端字节序(Little Endian):高序字节存储在高位地址,低序字节存储在低位地址
存储方式
32 位整数 0x12345678 是从起始位置为 0x00 的地址开始存放,则:
| 内存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
大端小端图片

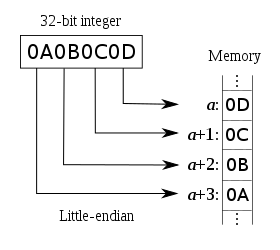
判断大端小端
判断大端小端
可以这样判断自己 CPU 字节序是大端还是小端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std;
int main()
{
int i = 0x12345678;
if (*((char*)&i) == 0x12)
cout << "大端" << endl;
else
cout << "小端" << endl;
return 0;
}
各架构处理器的字节序
- x86(Intel、AMD)、MOS Technology 6502、Z80、VAX、PDP-11 等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)等处理器为大端序;
- ARM(默认小端序)、PowerPC(除 PowerPC 970 外)、DEC Alpha、SPARC V9、MIPS、PA-RISC 及 IA64 的字节序是可配置的。
网络字节序
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用:大端(Big Endian)排列方式。
TCP 与 UDP 的区别
- TCP 面向连接,UDP 是无连接的;
- TCP 提供可靠的服务,也就是说,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付
- TCP 的逻辑通信信道是全双工的可靠信道;UDP 则是不可靠信道
- 每一条 TCP 连接只能是点到点的;UDP 支持一对一,一对多,多对一和多对多的交互通信
- TCP 面向字节流(可能出现黏包问题),实际上是 TCP 把数据看成一连串无结构的字节流;UDP 是面向报文的(不会出现黏包问题)
- UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 IP 电话,实时视频会议等)
- TCP 首部开销20字节;UDP 的首部开销小,只有 8 个字节
TCP 黏包问题
原因
TCP 是一个基于字节流的传输服务(UDP 基于报文的),“流” 意味着 TCP 所传输的数据是没有边界的。所以可能会出现两个数据包黏在一起的情况。
解决
- 发送定长包。如果每个消息的大小都是一样的,那么在接收对等方只要累计接收数据,直到数据等于一个定长的数值就将它作为一个消息。
- 包头加上包体长度。包头是定长的 4 个字节,说明了包体的长度。接收对等方先接收包头长度,依据包头长度来接收包体。
- 在数据包之间设置边界,如添加特殊符号
\r\n标记。FTP 协议正是这么做的。但问题在于如果数据正文中也含有\r\n,则会误判为消息的边界。 - 使用更加复杂的应用层协议。
TCP 传输连接管理
因为 TCP 三次握手建立连接、四次挥手释放连接很重要,所以附上《计算机网络(第 7 版)-谢希仁》书中对此章的详细描述:https://gitee.com/huihut/interview/raw/master/images/TCP-transport-connection-management.png
{kind=link}
TCP 三次握手建立连接
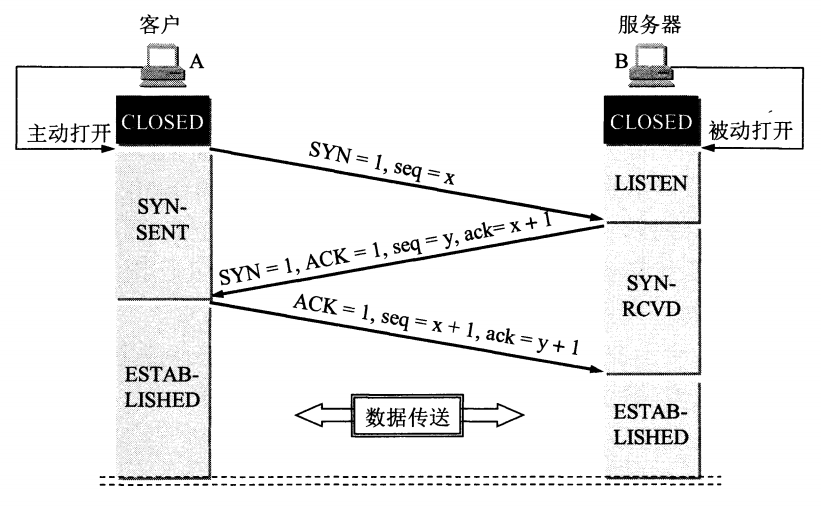
【TCP 建立连接全过程解释】
- 客户端发送 SYN 给服务器,说明客户端请求建立连接;
- 服务端收到客户端发的 SYN,并回复 SYN+ACK 给客户端(同意建立连接);
- 客户端收到服务端的 SYN+ACK 后,回复 ACK 给服务端(表示客户端收到了服务端发的同意报文);
- 服务端收到客户端的 ACK,连接已建立,可以数据传输。
TCP 为什么要进行三次握手?
【答案一】因为信道不可靠,而 TCP 想在不可靠信道上建立可靠地传输,那么三次通信是理论上的最小值。(而 UDP 则不需建立可靠传输,因此 UDP 不需要三次握手。)
【答案二】因为双方都需要确认对方收到了自己发送的序列号,确认过程最少要进行三次通信。
【答案三】为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
TCP 四次挥手释放连接
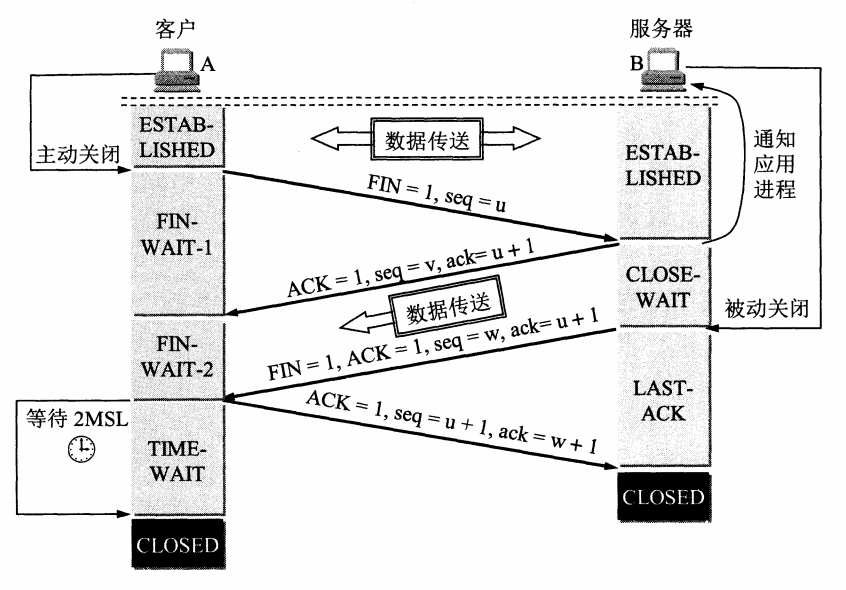
【TCP 释放连接全过程解释】
- 客户端发送 FIN 给服务器,说明客户端不必发送数据给服务器了(请求释放从客户端到服务器的连接);
- 服务器接收到客户端发的 FIN,并回复 ACK 给客户端(同意释放从客户端到服务器的连接);
- 客户端收到服务端回复的 ACK,此时从客户端到服务器的连接已释放(但服务端到客户端的连接还未释放,并且客户端还可以接收数据);
- 服务端继续发送之前没发完的数据给客户端;
- 服务端发送 FIN+ACK 给客户端,说明服务端发送完了数据(请求释放从服务端到客户端的连接,就算没收到客户端的回复,过段时间也会自动释放);
- 客户端收到服务端的 FIN+ACK,并回复 ACK 给服务端(同意释放从服务端到客户端的连接);
- 服务端收到客户端的 ACK 后,释放从服务端到客户端的连接。
TCP 为什么要进行四次挥手?
【问题一】TCP 为什么要进行四次挥手? / 为什么 TCP 建立连接需要三次,而释放连接则需要四次?
【答案一】因为 TCP 是全双工模式,客户端请求关闭连接后,客户端向服务端的连接关闭(一二次挥手),服务端继续传输之前没传完的数据给客户端(数据传输),服务端向客户端的连接关闭(三四次挥手)。所以 TCP 释放连接时服务器的 ACK 和 FIN 是分开发送的(中间隔着数据传输),而 TCP 建立连接时服务器的 ACK 和 SYN 是一起发送的(第二次握手),所以 TCP 建立连接需要三次,而释放连接则需要四次。
【问题二】为什么 TCP 连接时可以 ACK 和 SYN 一起发送,而释放时则 ACK 和 FIN 分开发送呢?(ACK 和 FIN 分开是指第二次和第三次挥手)
【答案二】因为客户端请求释放时,服务器可能还有数据需要传输给客户端,因此服务端要先响应客户端 FIN 请求(服务端发送 ACK),然后数据传输,传输完成后,服务端再提出 FIN 请求(服务端发送 FIN);而连接时则没有中间的数据传输,因此连接时可以 ACK 和 SYN 一起发送。
【问题三】为什么客户端释放最后需要 TIME-WAIT 等待 2MSL 呢?
【答案三】
- 为了保证客户端发送的最后一个 ACK 报文能够到达服务端。若未成功到达,则服务端超时重传 FIN+ACK 报文段,客户端再重传 ACK,并重新计时。
- 防止已失效的连接请求报文段出现在本连接中。TIME-WAIT 持续 2MSL 可使本连接持续的时间内所产生的所有报文段都从网络中消失,这样可使下次连接中不会出现旧的连接报文段。
TCP 有限状态机
TCP 有限状态机图片

HTTP
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP 是万维网的数据通信的基础。
请求方法
| 方法 | 意义 |
|---|---|
| OPTIONS | 请求一些选项信息,允许客户端查看服务器的性能 |
| GET | 请求指定的页面信息,并返回实体主体 |
| HEAD | 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| DELETE | 请求服务器删除指定的页面 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
状态码(Status-Code)
- 1xx:表示通知信息,如请求收到了或正在进行处理
- 100 Continue:继续,客户端应继续其请求
- 101 Switching Protocols 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到 HTTP 的新版本协议
- 2xx:表示成功,如接收或知道了
- 200 OK: 请求成功
- 3xx:表示重定向,如要完成请求还必须采取进一步的行动
- 301 Moved Permanently: 永久移动。请求的资源已被永久的移动到新 URL,返回信息会包括新的 URL,浏览器会自动定向到新 URL。今后任何新的请求都应使用新的 URL 代替
- 4xx:表示客户的差错,如请求中有错误的语法或不能完成
- 400 Bad Request: 客户端请求的语法错误,服务器无法理解
- 401 Unauthorized: 请求要求用户的身份认证
- 403 Forbidden: 服务器理解请求客户端的请求,但是拒绝执行此请求(权限不够)
- 404 Not Found: 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置 “您所请求的资源无法找到” 的个性页面
- 408 Request Timeout: 服务器等待客户端发送的请求时间过长,超时
- 5xx:表示服务器的差错,如服务器失效无法完成请求
- 500 Internal Server Error: 服务器内部错误,无法完成请求
- 503 Service Unavailable: 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的 Retry-After 头信息中
- 504 Gateway Timeout: 充当网关或代理的服务器,未及时从远端服务器获取请求
更多状态码:菜鸟教程 . HTTP状态码
算法
todo
开放性问题
- 线程和进程的联系和区别
- 线程有哪几种状态
- 进程间的通信方式
- 使用过的 shell 命令
- 使用过的 vim 命令
- 使用过的 gdb 命令
- 请用简单的语言告诉我C++ 是什么?
- C和C++的区别?
- 什么是面向对象(OOP)?
- 什么是多态?
- STL库用过吗?常见的STL容器有哪些?算法用过哪几个?
- 解释下封装、继承和多态?
- TCP和UDP通信的差别?什么是IOCP?
- 说下你对内存的了解?
- HTTP和HTTPS的主要区别
- 如何设计一个高并发的系统
更多开放性问题参考: C++面试集锦( 面试被问到的问题 )
参考
- 📚 C/C++ 技术面试基础知识总结,包括语言、程序库、数据结构、算法、系统、网络、链接装载库等知识及面试经验、招聘、内推等信息。
- 🔥 计算机学习路线,计算机网络、操作系统、C++、Java 等面试复习题库
- Python面试常见的170道题目的解析和源码